Companies in the energy industry face several challenges when it comes to streamlining large datasets, finding compatibility among applications, and visualizing different types of data in real-time. The latest release of INT’s IVAAP Data Visualization Platform focuses on solving these challenges by making it more efficient to find and manage subsurface data.
Seamless visualization of domain data goes beyond just accessing the data in the cloud — to maximize your workflow, you must be able to search through data quickly, execute processes and workflows, and visualize the results in one platform. IVAAP’s custom SDK embeds IVAAP’s widgets in users’ applications to add the flexibility to customize the interface, connectors, and a dynamic UX/UI.
New & Improved Widgets: Diagram, Image, Well Log, and 3D
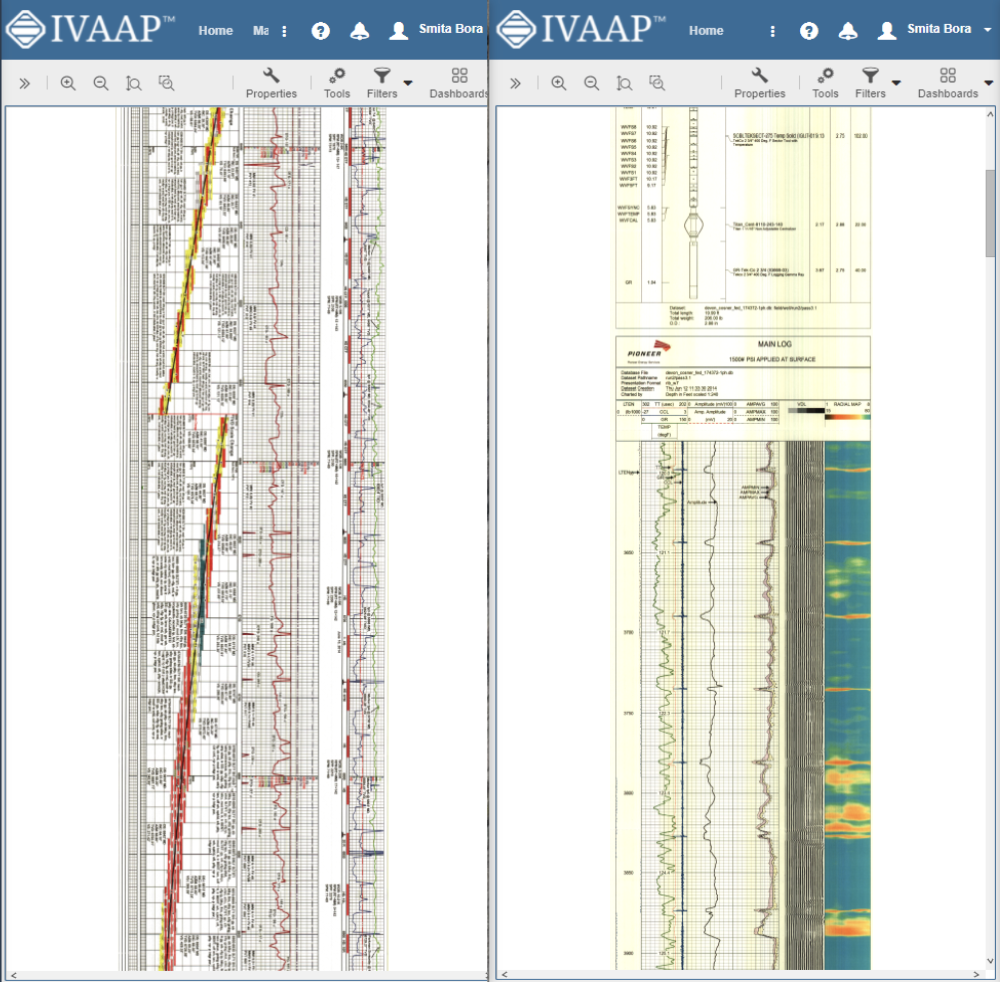
A new widget has been added to IVAAP’s list of widgets — the diagram widget. The diagram widget displays SVG data from IVAAP combined with numerical curve values in real-time, supporting animations of your data. The image widget has been improved to support very large TIFFs (Tiled Image Support). Users can visualize their large raster image files by saving them in the cloud and IVAAP creates a single point of access to these files, making compressed rendering images from their original format.
We also added improvements to other existing widgets. IVAAP’s existing WellLog widget offers Single Data, Multi Data, and Multi Parent modes to display very complex well logs and switch between wells smoothly. The 3D visualization widget’s high performance reservoir visualization is now combined with curser tracking between 3D Basemap and 2D seismic lines and overlay. The basemap feature also supports tops, faults, point sets, and more.
Empowering Subsurface Workflows
IVAAP has offered the ability to connect to any third-party application for a while, allowing users to integrate in-house workflows and customize visualizations to create a seamless experience. For many companies with data located in more than one repository or cloud database, accessing all of this data through one unique portal streamlines the process and standardizes data access. IVAAP can communicate with external engines, such as ML platforms, processing engines — Tensorflow and SageMaker— and code can be written in Python and executed through the IVAAP client interface.
With these new and improved features, IVAAP 2.9 enables easy search and visualization of energy, geophysical, and production data in the cloud. It allows product owners, developers, and architects to build subsurface digital solutions faster without having to start from scratch.
For more information, please visit www.int.com or contact us at intinfo@int.com.
Visit us online at int.com/ivaap for a preview of IVAAP or for a demo of INT’s other data visualization products.