In our recent webinar, we had the privilege of featuring Débora Ribeiro Barretto, Geophysicist, and OSDU® Focal Point, who shared insights into their OSDU® implementation journey. Titled “Fundação Gorceix OSDU Implementation: Experience, Challenges, and the Road Ahead,” the session delved into the Foundation’s objectives, accomplishments, and the evolving role they envision within the OSDU Forum.
Fundação Gorceix: Pioneering Innovation in Brazil
Fundação Gorceix, a Brazilian institution dedicated to technology and science, operates at the forefront of mining, environment, and oil and gas sectors. The Department of Petroleum Geology, a key arm of the Foundation, is committed to evaluating Brazil’s oil potential. Managing geophysical data through the RDG (Rede de Dados Geofisicos), a sophisticated infrastructure, Fundação Gorceix optimizes communication among partner companies and operators in Brazil’s oil and gas sector.
OSDU Implementation: Transforming Workflows with AWS Cloud
Fundação Gorceix’s primary objective focuses on enhancing geophysical and geological data workflows through the OSDU Data Platform in the AWS cloud. A streamlined workflow illustrated the transition from on-premise data handling to a robust OSDU and AWS infrastructure. This transformation promises a more efficient process involving data ingestion into the OSDU Data Platform and consumption via the INT IVAAP platform.

The introduction of a virtual data room, facilitated by OSDU, emerged as a game-changer, providing global, secure access and ensuring legal and compliance entitlements.
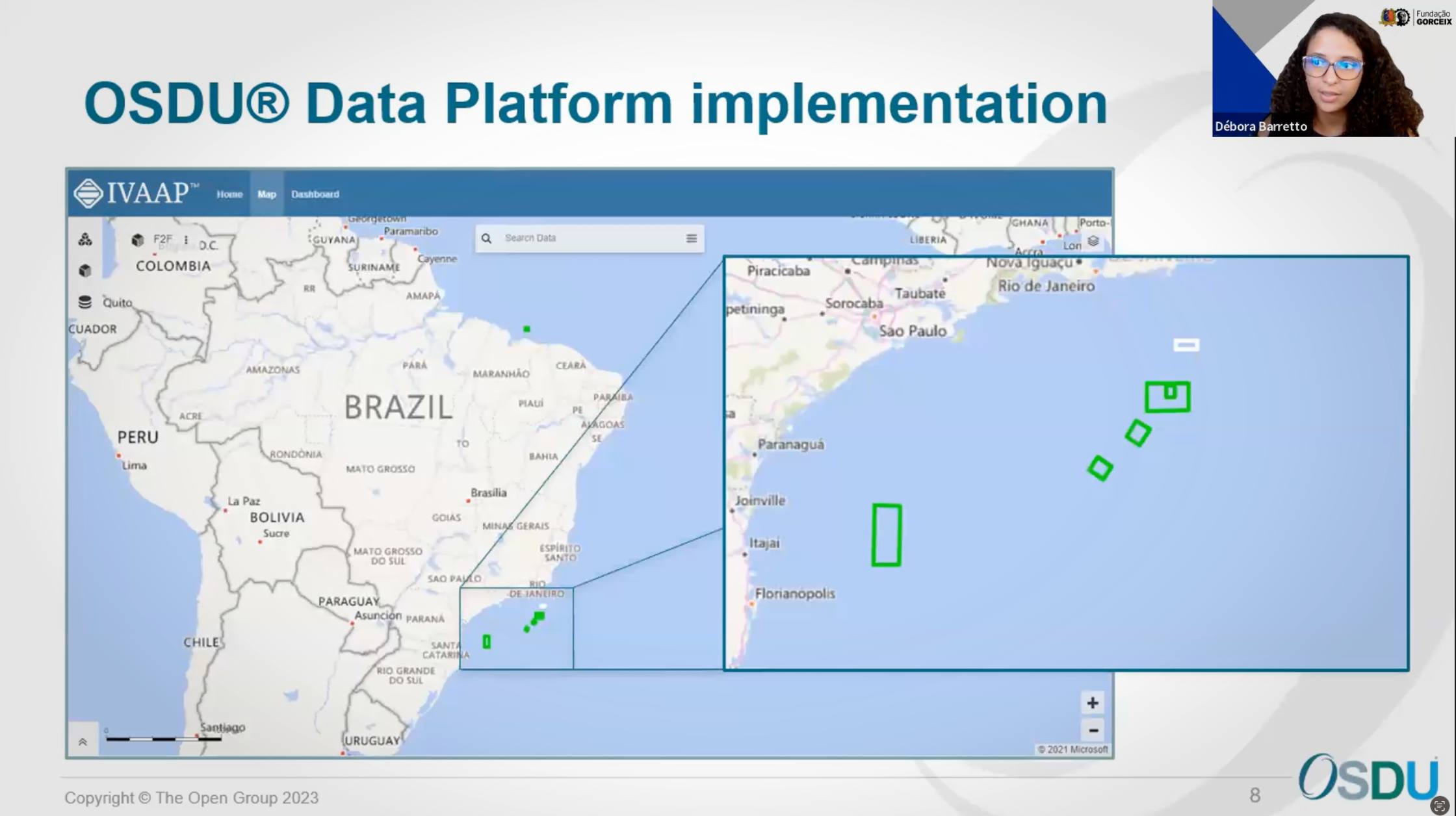
A glimpse of successfully ingested Brazilian data highlighted the platform’s capabilities in managing diverse datasets.
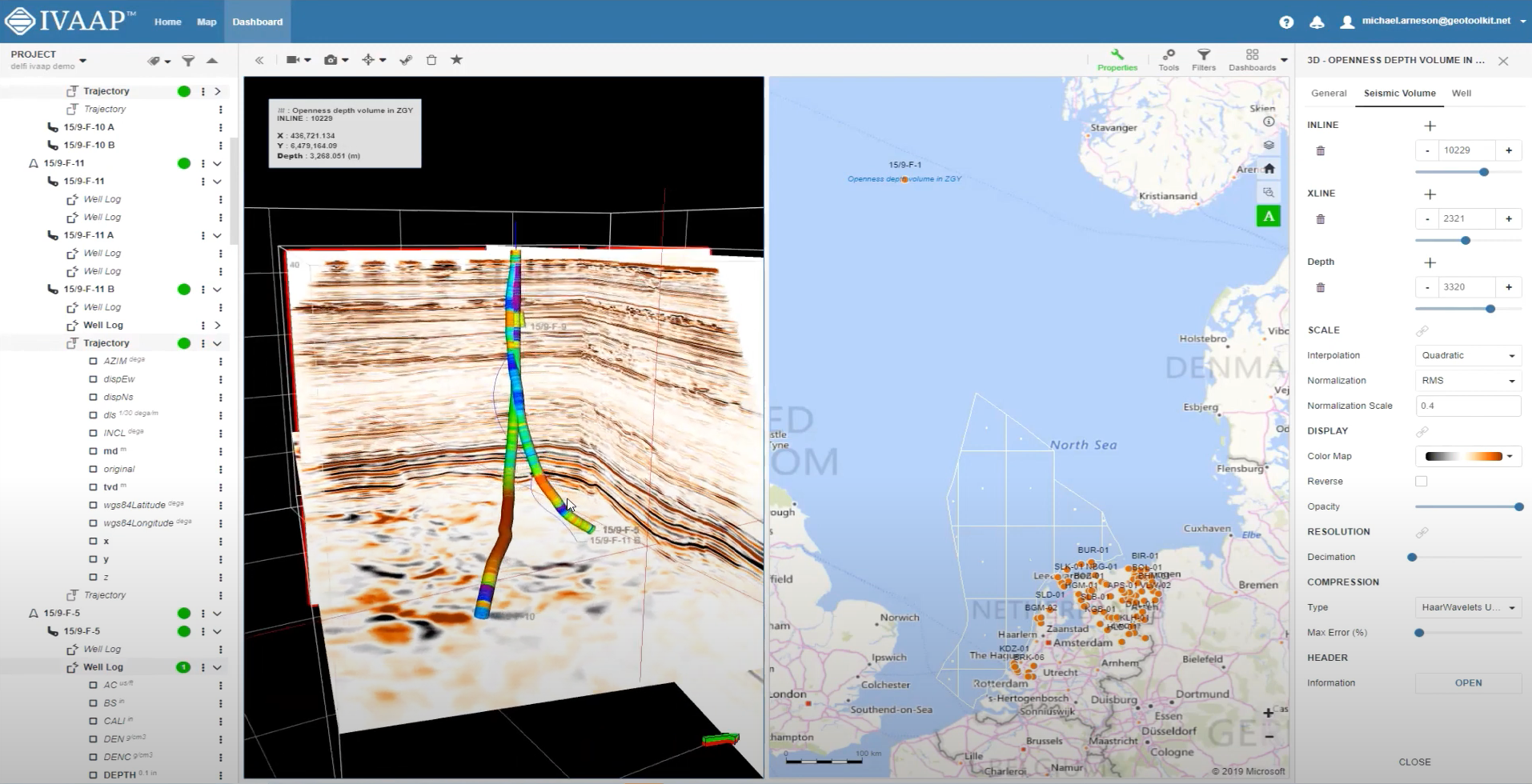
For each project, some selected seismic and well data and other relevant streaming data will be available in IVAAP.
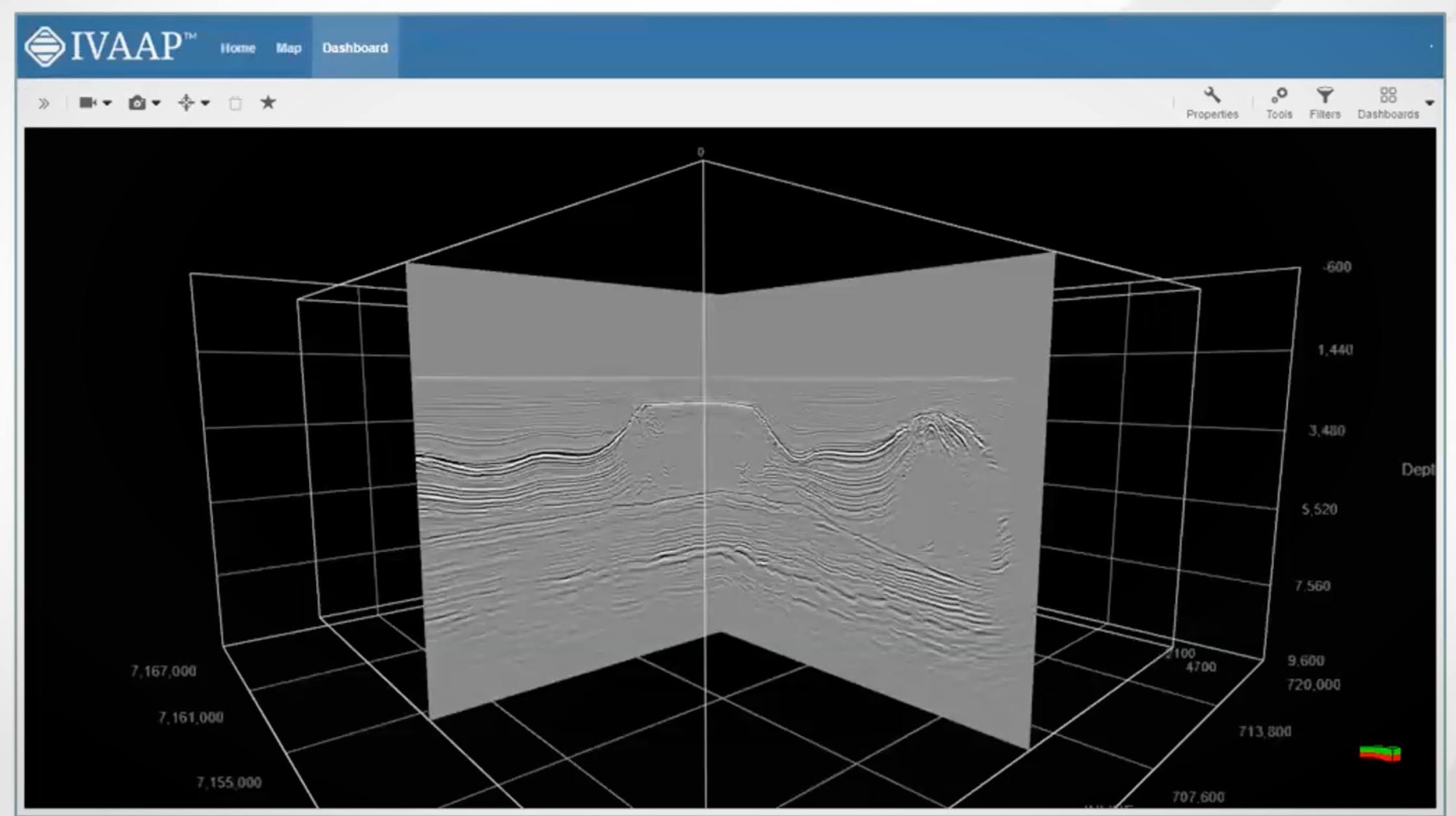
Example of ingested Brazilian seismic data
A Journey of Challenges and Triumphs
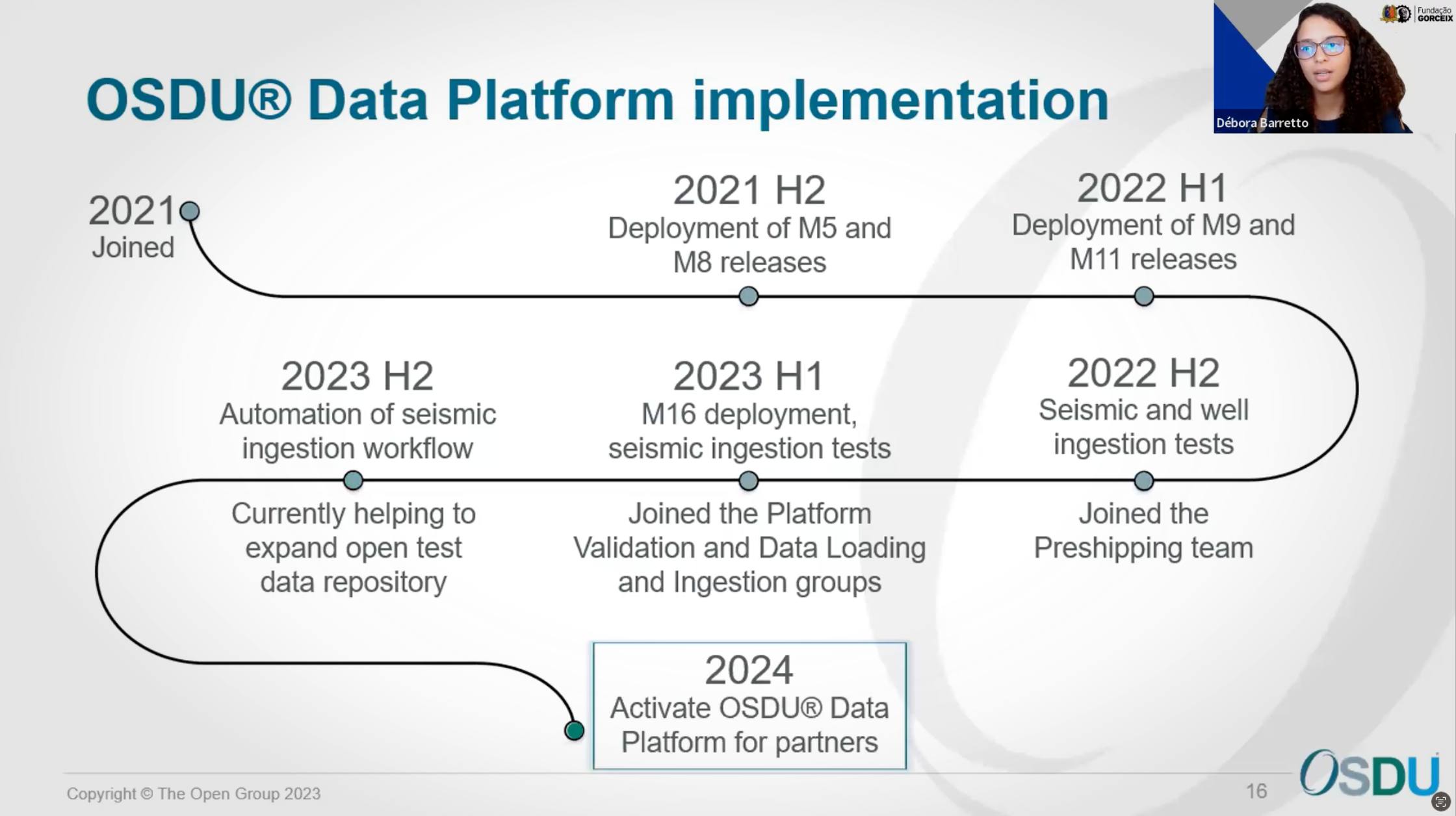
A candid exploration of the challenges encountered during Fundação Gorceix’s OSDU journey underscored the importance of dedicated teams and strategic focus. Issues with deployment time and operational functionality were met with resilience and a commitment to improvement. The transition to a fully dedicated team in the second semester of the first year proved pivotal, leading to a functional M11 release and the inaugural ingestion of Brazilian well and seismic data.

Shaping the Future: Automation and Collaboration
Transitioning to the forward-looking aspect of Fundação Gorceix’s OSDU journey, the organization redirected its focus to validating and enhancing seismic data ingestion in 2023. The incorporation of automation tools, engagement with other softwares, and active participation in forum groups showcased a commitment to continuous improvement. Looking ahead to 2024, the objective is to activate a virtual room with the OSDU Data Platform and IVAAP, presenting partners with seamlessly ingested data for consumption.
Fundação Gorceix, through its dedicated efforts and collaboration with the OSDU Forum community, partners, INT, IesBrazil, and AWS, made significant contributions to surmounting the intricate challenges of this transformative process. Their involvement included addressing time-consuming deployment, preparing Brazilian seismic data, navigating diverse coordinate reference systems, and overcoming the obstacles a lean, non-multidisciplinary team posed.
Collaborative Success: A Call to Contribute
The presentation wrapped up with a compelling message — The OSDU Forum is not designed solely for its members; rather, it is formed collaboratively by the engaged participants within the community. The call for engagement and collaboration resonated profoundly, emphasizing the importance of collective contribution. Fundação Gorceix eagerly anticipates operating the OSDU virtual data room in the near future, reciprocating the support received by contributing to the community.
In embracing the journey of Fundação Gorceix, it becomes evident that challenges are inherent to innovation. With teamwork, resilience, and a collaborative spirit, shared success becomes an achievable and rewarding endeavor. The OSDU Data Platform stands as a testament to the strength derived from collaborative efforts to establish a platform for shared knowledge and mutual support.
Watch the on-demand webinar here to dive deeper into Fundação Gorceix’s OSDU journey.
Visit us online at int.com/ivaap for a preview of IVAAP or for a demo of INT’s other data visualization products.
For more information, please visit www.int.com or contact us at intinfo@int.com.
____________
ABOUT INT
INT software empowers energy companies to visualize their complex data (geoscience, well, surface reservoir, equipment in 2D/3D). INT offers a visualization platform (IVAAP) and libraries (GeoToolkit) that developers can use with their data ecosystem to deliver subsurface solutions (Exploration, Drilling, Production). INT’s powerful HTML5/JavaScript technology can be used for data aggregation, API services, and high-performance visualization of G&G and energy data in a browser. INT simplifies complex subsurface data visualization.
INT, the INT logo, and IVAAP are trademarks of Interactive Network Technologies, Inc., in the United States and/or other countries.